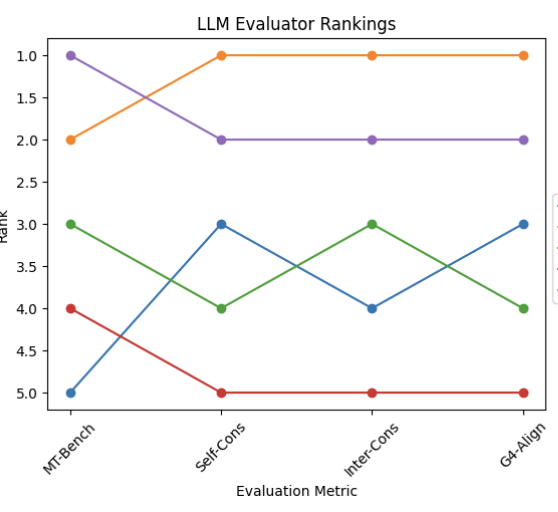
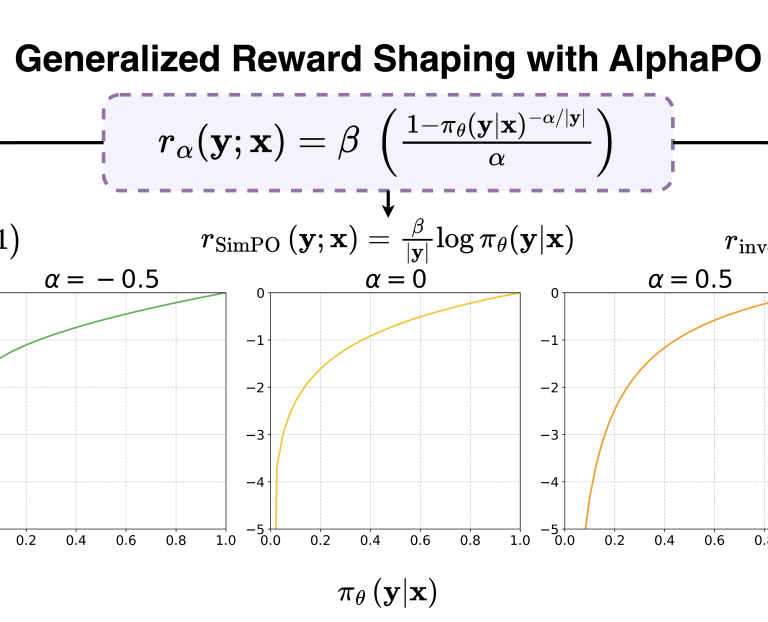
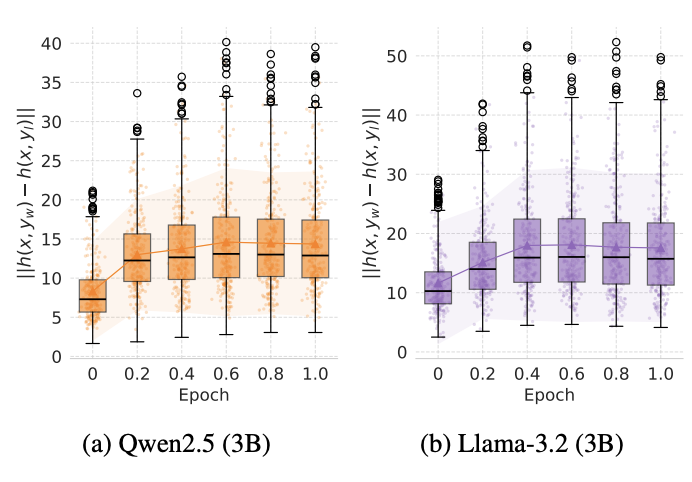
2025 AlphaPO - Reward Shape Matters for LLM Alignment Aman Gupta, Shao Tang, Qingquan Song, and 8 more authors ICML, 2025 arXiv On the Robustness of Reward Models for Language Model Alignment Jiwoo Hong, Noah Lee, Eunki Kim, and 5 more authors ICML, 2025 arXiv Cross-lingual Transfer of Reward Models in Multilingual Alignment Jiwoo Hong*, Noah Lee*, Rodrigo Martínez-Castaño, and 2 more authors NAACL, 2025 arXiv Code The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models Seungone Kim, Juyoung Suk, Ji Yong Cho, and 29 more authors NAACL (Best Paper), 2025 arXiv Evaluating the Consistency of LLM Evaluators Noah Lee*, Jiwoo Hong*, and James Thorne COLING, 2025 arXiv 2024 ORPO: Monolithic Preference Optimization without Reference Model Jiwoo Hong, Noah Lee, and James Thorne EMNLP, 2024 arXiv Code Margin-aware Preference Optimization for Aligning Diffusion Models without Reference Jiwoo Hong*, Sayak Paul*, Noah Lee, and 3 more authors Preprint, 2024 arXiv Code 2023 Can Large Language Models Capture Dissenting Human Voices? Noah Lee*, Na Min An*, and James Thorne EMNLP, 2023 arXiv Code
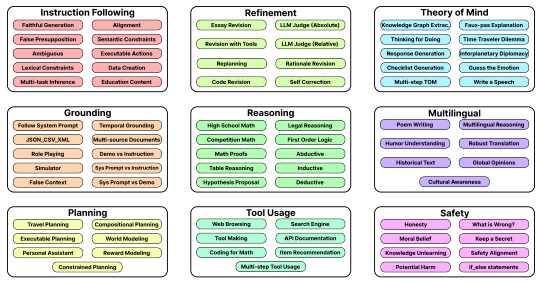 The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language ModelsNAACL (Best Paper), 2025
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language ModelsNAACL (Best Paper), 2025